I was invited to present iMorphia at the Festival of Fools event on April 1st 2017, hosted by the Nottingham Dilettante Society and the theatre group NonSuch.
This was a great opportunity to create a range of alternative foolish characters and update iMorphia so people could choose a character to inhabit, or be given one at random.
Around twenty visitors experienced iMorphia, changing gender and body type, going anime or naked with body tattoos, play acting, dancing, laughing and having fun being foolish.
Visitors don a white boiler suit, wear video glasses and facing the projector and body tracking Kinect, a virtual character is projected onto their body.
“I’d describe the iMorphia experience as fantastically discombobulating.”
(Sophie Gargett, Dilettante Society)
Visitors inhabiting a range of projected virtual characters are shown in the video below.
By pressing a mouse button, the new version enabled the instant changing of a character between male and female, plus the addition or not of tattoos. Rather than costuming the characters, I chose to create naked characters using the latest edition of MakeHuman. The idea of a person donning a white boiler suit over their clothes then appearing virtually naked I felt added an element of risk and surreal drama to the occasion.
Five visitors to the exhibition chose to experience iMorphia whilst a small audience watched the proceedings. Positive feedback from the participants and audience confirmed the effectiveness of the illusion in producing a strange and disturbing unworldly ghost like character. One person commenting that from a distance they thought they were watching a film, until they came closer and were surprised in realising the character was being projected onto and controlled in real time by a performer.
Recorded footage of iMorphia once again demonstrated how participants creatively exploited glitches produced by Kinect tracking errors. Laughter resulting from one of the participants breaking the tracking entirely by squatting down:
In post 18. Interactive Props and Physics it was noted “Colocation issues are the result of the difficulty in perceiving where the character is in three dimensional space due to the lack of depth perception.”
In this enactment the Oculus Rift VR headset is used as a means of ascertaining whether the added depth perception of the stereoscopic rendering of the Unity scene might assist in enabling a perfomer to locate the virtual props in 3D space.
Three enactments were carried out, two with the rendered viewpoint from the camera located from the audience perspective and one from the first person perspective typically used in VR and gaming.
The video below is a mobile phone recording of a computer monitor rendering the Unity scene in real time. The computer uses an i7 processor and a relatively powerful Nvidia GT 720 graphics card to deliver the stereoscopic rendering to the Oculus Rift. Though the system is able to support the new Kinect v2, the older Kinect was used in order to maintain continuity with previous enactments.
In the first enactment myself and one of the previous performers carried out the task of knocking the book off the table. We both felt that the task was much easier to accomplish with the stereoscopic depth enabling one to easily judge the position of the avatars hand in relationship to the virtual book.
Kinect tracking errors made bending the arm and precise control of the hand a little problematic. The task was felt to be much easier to achieve than previous enactments using the monoscopic video camera perspective as it was possible to clearly see where the virtual hand was, even if when it was ‘misbehaving’.
However with the added depth perception a new issue came to be highlighted that was previously unnoticed, that of difficulties in knowing front from back. When one moves ones hand forward it moves away from you, whilst when viewed from the camera perspective the hand moves nearer to the camera, the opposite direction to which one is used to. This effect parallels the left right reversal of a mirror in comparison to the camera view. In both cases through practice it is possible to become accustomed to the depth reversal and lack of mirror reversal, though at first one finds oneself moving in the opposite direction, or using the opposite limb, It is possible to technically produce a mirror reversal, but a depth reversal was felt to be more problematic. A simpler solution, easily achievable using VR was to give the performer the same first person perspective as one is normally used to – seeing the scene from the viewpoint of the avatar. In the video, the third enactment carried out by myself demonstrates this perspective.
Due to time constraints it was not possible to test this enactment with the external participant. However despite the incredibly immersive qualities of the first person perspective, I felt there are some serious problems resulting from this viewpoint.
Firstly I felt a very strange out of the body experience looking down at a virtual body that was not mine, in addition my virtual limbs and my height were completely different to my own and this produced a strong sense of disorientation. Perhaps a male body of similar height and dimensions to my own might have felt more familiar.
The task of knocking the book over felt extremely easy as I could see my virtual hand in relationship to the book from a familiar first person perspective. Despite Kinect tracking issues, it was possible to correct the position of the hand and ultimately knocking the book over was easy to achieve. Both the issues of depth and mirror reversal were removed using this perspective.
However walking and moving in the scene resulted in a strong degree of vertigo and dizziness. For the first time I experienced “VR motion sickness” and nearly fell over. It was extremely unpleasant!
Further, after taking the headset off, for some minutes I still felt disorientated, somewhat dizzy and a little out of touch with reality.
Although the first person perspective should have felt the most natural, it also produced disturbing side effects which if not rectified would make the first person VR perspective unusable if not hazardous in a live performance context.
The feelings of vertigo and motion sickness may well have been exaggerated due to Kinect tracking issues, with the avatar body moving haphazardly resulting in a disconnect between the viewpoint rendered by the avatars perspective and that of where my real head thought it was.
Two further practical considerations are: i) the VR headset is tethered by two cables making it difficult to move feely and safely and ii) the headset being enclosed felt somewhat hot after a short period of time. Light, ‘breathable’ wireless VR headsets may solve these problems, but the effects of vertigo resulting from the first person perspective whilst moving in 3D space and feeling as if one is in another body are perhaps more problematic.
The simplest solution, though still with the depth reversal issue, is removing the VR tracking and to create a fixed virtual camera giving the audience perspective, parallel to the previous methodology of relaying the audience perspective through a video camera mounted on a tripod.
Before dismissing the VR first person perspective being the sole cause of motion sickness, it is planned that a further test be carried out using the more accurate Kinect v2 with a virtual body of proportions similar to my own. It is envisaged that the Kinect v2 would result in a more stable first person perspective and with a more familiar viewpoint as one I am used to with my natural body.
In addition other gaming like perspectives might also be tried, the third person perspective for instance, with a virtual camera located just above and behind the avatar.
A key realisation is that the performers perspective need not necessarily be that of the audience, that the iMorphia system might render two (or possibly more) perspectives – one for the audience – the projected scene, and one for the performer. The projected scene being designed to produce the appropriate suspension of disbelief for the audience, whilst the performer’s perspective designed to enable the performer to perform efficiently such that the audience believes the performer to be immersed and present in the virtual scene.
A workshop involving two performers was carried out in order to re-evaluate the performative notions of participation and navigation (Dixon 2007), described in post 15. Navigation.
Previously a series of auto-ethnographic enactments (documented in posts August-December 2015) provided some initial feedback on participation and navigation with iMorphia . It was interesting to observe the enactments as a witness rather than a participant and to see if the performers might experience similar problems and effects as I had.
Participation
The first study was of participation – with the performer interacting with virtual props. Here the performer was given two tasks, first to try and knock the book off the table, then to knock over the virtual furniture, a table and a chair.
The first task involving the book proved extremely difficult, with both performers confirming the same problem as I had encountered, namely knowing where the virtual characters hand was in relationship to ones own real body. This is a result of a discrepancy in collocation between the real and the virtual body compounded by a lack of three dimensional or tactile feedback. One performer commenting “it makes me realise how much I depend on touch” underlining how important tactile feedback is when we reach for and grasp an object.
The second task of knocking the furniture was accomplished easily by by both performers and prompted gestures and exclamations of satisfaction and great pleasure!
In both cases, due to the lack of mirroring in the visual feedback, initially both performers tended to either reach out with the wrong arm or move in the wrong direction when attempting to move towards or interact with a virtual prop. This left/right confusion has been noted in previous tests as we are so used to seeing ourselves in a mirror that we automatically compensate for the horizontal left right reversal.
An experiment carried out in June 2015 confirmed that a mirror image of the video would produce the familiar inversion we are used to seeing in a mirror and performers did not experience the left/right confusion. It was observed that the mirroring problem appeared to become more acute when given a task to perform involving reaching out or moving towards a virtual object.
Navigation
The second study was of navigation through a large virtual set using voice commands and body orientation. The performer can look around by saying “Look” then using their body orientation to rotate the viewpoint. “Forward” would take the viewpoint forward into the scene whilst “Backward” would make the scene retreat as the character walks out of the scene towards the audience. Control of the characters direction is again through body orientation. “Stop” makes the character stationary.
Two tests were carried out, one with the added animation of the character walking when moving, the other without the additional animation. Both performers remarking how the additional animation made them feel more involved and embodied within the scene.
Embodiment became a topic of conversation with both performers commenting on how landmarks became familiar after a short amount of time and how this memory added to their sense of being there.
The notions of avatar/player relationship, embodiment, interaction, memory and visual appearance are discussed in depth in the literature on game studies and is an area I shall be drawing upon in a deeper written analysis in due course.
Finally we discussed how two people might be embodied and interact with the enactments of participation and navigation. Participation with props was felt to be easier, whilst navigation might prove problematic, as one person has to decide and controls where to go.
A prototype two performer participation scene comprising two large blocks was tested but due to Unity problems and lack of time this was not fully realised. The idea being to enable two performers to work together to lift and place large cubes so as to construct a tower, rather like a children’s toy wood brick set.
Navigation with two performers is more problematic, even if additional performers are embodied as virtual characters , they would have to move collectively with the leader, the one who is controlling the navigation. However this might be extended to allow characters to move around a virtual set once a goal is reached or perhaps navigational control might be handed from one participant to another.
It was also observed that performers tended to lose a sense of which way they were facing during navigation. This is possibly due to two reasons – the focus on steering during navigation such that the body has to rotate more and the lack of clear visual feedback as to which way the characters body is facing, especially during moments of occlusion when the character moves through scenery such as undergrowth.
These issues of real space/virtual space colocation, performer feedback of body location and orientation in real space would need to be addressed if iMorphia were to be used in a live performance.
The video documentation below illustrates an enactment of iMorphia with props imbued with physics. The addition of rigid body colliders and physical materials to the props and the limbs of the avatar enables Unity to simulate in real time the physical collision of objects and the effects of gravity, weight and friction.
The physics simulation adds a degree of believability to the scene, as the character attempts to interact with the book and chair. The difficulty of control in attempting to make the character interact with the virtual props is evident, resulting in a somewhat comic effect as objects are accidentally knocked over.
Interaction with the physics imbued props produced unpredictable responses to performance participation, resulting in a dialogue between the virtual props and the performer. These participatory responses suggest that physics imbued props produce a greater sense of engagement through enhancing the suspension of disbelief – the virtual props appear more believable and realistic than those that not imbued with physics.
This enactment once again highlights the problem of colocation between the performer, the projected character and the virtual props. Colocation issues are the result of the difficulty in perceiving where the character is in three dimensional space due to the lack of depth perception. There are also navigational problems resulting from an incongruity between the mapping of the position of the performers body and limbs in real space and those of the virtual characters avatar in virtual space.
In this experimental enactment I created a minimalist stage like set consisting of a chair and a table on which rests a book.
The video below illustrates some of the issues and problems associated with navigating the set and possible interactions between the projected character and the virtual objects.
Problems and issues:
1. Projected body mask and perspective As the performer moves away from the kinect, the virtual character shrinks in size such that the projected body mask no longer matches the performer. Additional scripting to control the size of the avatar or altering the code in the camera script might compensate for these problems, though there may be issues associated with the differences between movements and perceived perspectives in the real and virtual spaces.
2. Colocation and feedback
The lack of three dimensional feedback in the video glasses results in the performer being unable to determine where the virtual character is in relationship to the virtual objects and thereby unable to successfully engage with the virtual objects in the scene.
3. Real/virtual interactions
There are issues associated with interactions between the virtual character and the virtual objects. In this demonstration objects can pass through each other. In the Unity games engine it is possible to add physical characteristics so that objects can push against each other, but how might this work? Can the table be pushed or should the character be stopped from moving? What are the appropriate physical dynamics between objects and characters? Should there be additional feedback, perhaps in the form of audio to represent tactile feedback when a character comes into contact with an object?
How might the book be picked up or dropped? Could the book be handed to another virtual character?
Rather than trying to create a realistic world where objects and characters behave and interact ‘normally’ might it be more appropriate and perhaps easier to go around the problems highlighted above and create surreal scenarios that do not mimic reality?
Since the last enactment exploring navigation, I have been looking to implement performative interaction with virtual objects – the theatrical equivalent of props – in order to facilitate Dixon’s notions of participation, conversation and collaboration.
I envisaged implementing a system that would enable two performers to interact with virtual props imbued with real world physical characteristics. This would then give rise to a variety of interactive scenarios – a virtual character might for instance choose and place a hat on the head of the other virtual character, pick up and place a glass onto a shelf or table, drop the glass such that it breaks, or collaboratively create or knock down a construction of virtual boxes. These types of scenarios are common in computer gaming, the challenge here however, would be to implement the human computer interfacing necessary to support natural unencumbered performative interaction.
This ambition raises a number of technical challenges, including the implementation of what is likely to be non-trivial scripting and the requirement of fast, accurate body and gesture tracking, perhaps using the Kinect 1.
There are also technical issues associated with the colocation of the performer and the virtual objects and the need for 3D visual feedback to the performer. These problems were encountered in the improvisation enactment with a virtual ball and discussed in section “3. Depth and Interaction” in post 14. Improvisation Workshop.
The challenges associated with implementing real world interaction with virtual 3D objects are currently being met by Microsoft Research in their investigations of augmented reality through prototype systems such as Mano-a-Mano and their latest project, the Hololens.
“Mano-a-Mano is a unique spatial augmented reality system that combines dynamic projection mapping, multiple perspective views and device-less interaction to support face-to-face, or dyadic, interaction with 3D virtual objects.”
“Microsoft HoloLens understands your gestures, gaze, and voice, enabling you to interact in the most natural way possible”
Reviews of the Hololens suggest natural interaction with the virtual using the body, gesture and voice is problematic, with issues of lag, and the misreading of gestures, similar to the problems I encountered during 15. Navigation.
“While voice controls worked, there was a lag between giving them and the hologram executing them. I had to say, “Let it roll!” to roll my spheres down the slides, and there was a one second or so pause before they took a tumble. It wasn’t major, but was enough to make me feel like I should repeat the command.
Gesture control was the hardest to get right, even though my gesture control was limited to a one-fingered downward swipe”
During today’s supervision meeting it was suggested that instead of trying to achieve the interactive fidelity I have been envisaging, which is likely to be technically challenging, that I work around the problem and exploit the limitations of what is possible using the current iMorphia system.
One suggestion was that of implementing a moving virtual wall which the performer has to interact with or respond to. This raises issues of how the virtual wall responds to or effects the virtual performer and then how the real performer responds. Is it a solid wall, can it pass through the virtual performer? Other real world physical characteristics might imbued in the virtual prop such as weight or lightness; leading to further performative interactions between real performer, virtual performer and virtual object.
At the last workshop, a number of participants expressed the desire to be able to enter into the virtual scene. This would be difficult in the 2D environment of PopUpPlay but totally feasible with iMorphia, implemented in the 3D Games Engine, Unity.
Frank Abbott, one of the participants, suggested the idea of architectural landscape navigation, with a guide acting as a story teller and that the short story “The Domain of Arnheim” by Edgar Allen Poe might be inspirational in developing navigation within iMorphia.
The discussion continued with recollections of the effectiveness of early narrative and navigational driven computer games such as “Myst”.
Steve Dixon in “Digital Performance ” suggests four types of performative interaction with technology (Dixon, 2007, p. 563):
Navigation
Participation
Conversation
Collaboration.
The categories are ordered in terms of complexity and depth of interaction, 1 being the simplest and 4 the more complex. Navigation is where the performer steers through the content, this might be spatially as in a video game or via hyper links. Participation is where the performer undergoes an exchange with the medium. Conversation is where the performer and the medium undergo a back and forth dialogue. Collaboration is where participants and media interact produce surprising outcomes, as in improvisation.
It is with these ideas I began investigating the possibility of realising performative navigation in iMorphia. First I added a three dimensional landscape, ‘Tropical Paradise’ an asset supplied with an early version of Unity (v2.6, 2010).
Some work was required fixing shaders and scripts in order to make the asset run with the later version of Unity (v4.2, 2013) I was using.
I then began implementing control scripts that would enable a performer to navigate the landscape, the intention being to make navigation feel natural, enabling the unencumbered performer to seamlessly move from a conversational mode to a navigational one. Using the Kinect Extras package I explored combinations of spatial location, body movement, gesture and voice.
The following three videos document these developments. The first video demonstrates the use of gesture and spatial location , the second body orientation combined with gesture and voice and the third voice and body orientation with additional animation to enhance the illusion that the character is walking rather than floating through the environments.
Video 1: Gesture Control
Gestures: left hand out = look left, right hand out = look right, hand away from body = move forwards, hand pulled in = move backwards, both hands down = stop.
Step left or right = pan left/right.
The use of gesture to control the navigation proved problematic, it was actually very difficult to follow a path in the 3D world, and gestures were sometimes incorrectly recognised (or performed) resulting in navigational difficulties where a view gesture acted as a movement command or vice versa.
In addition the front view of the character did not marry well with the character moving into the landscape.
Further scripting and upgrading of the Kinect assets and Unity to v4.6 enabled the successful implementation of a combination of speech recognition, body and gesture control.
Video 2: Body Orientation, Gesture and Speech Control
Here the gesture of both hands out activates view control, where body orientation controls the view. This was far more successful than the previous version and the following of a path proved much easier.
Separating the movement control to voice activation ( “forward”, “back”, “stop”) helped in removing gestural confusion, however voice recognition delays resulted in overshooting when one wanted to stop.
The rotation of the avatar to face the direction of movement produced a greater sense of believability that the character is moving through a landscape. The addition of a walking movement would enhance this further – this is demonstrated in the third video.
Video 3: Body orientation and Speech Control
The arms out gesture felt a little contrived and so in the third demonstration video I added the voice command “look” to activate the change of view.
Realising the demonstrations took a surprising amount of work, with much time spent scripting and dealing with setbacks and pitfalls due to Unity crashes and compatibility issues between differing versions of assets and Unity. The Unity Kinect SDK and Kinect Extras assets proved invaluable in realising these demonstrations, whilst the Unity forums provided insight, support and help when working with quaternions, transforms, cameras, animations, game objects and the sharing of scripting variables. At some point in the future I intend to document the techniques I used to create the demonstrations.
There is much room for improvement and creating the demonstrations has led to speculation as to what an ideal form of performative interaction might be for navigational control.
For instance a more natural form of gestural recognition than voice control would be to recognise the dynamic gestures that correspond to walking forwards and backwards. According to the literature this is technically feasible, using for instance Neural Networks or Dynamic Time Warping, but these complex techniques are felt to be way beyond the scope of this research.
The object here is not to produce fully working robust solutions, instead the process of producing the demonstrations act as proof of concept and identify the problems and issues associated with live performance, navigation and control. The enactment and performance to camera serves to test out theory through practise and raises further questions and challenges.
Further Questions
How might navigation work with two performers?
Is the landscape too open and might it be better if constrained via fences, walls etc?
How might navigation differ between a large outside space and a smaller inside one, such as a room?
How might the landscape be used as a narrative device?
What are the differences between a gaming model for navigation where the player(s) are generally seated looking at a screen using a mouse/keyboard/controller and a theatrical model with free movement of one or more unencumbered performers on a stage?
What are the resulting problems and issues associated with navigation and the perspective of performers and audience ?
On the 26th and 27th May I carried out two workshops designed to compare improvisation and performative engagement between the two intermedial stages of PopUpPlay and iMorphia. The performers had previously participated in the last two workshops so were familiar with iMorphia, but had not worked with PopUpPlay before.
My sense that PopUpPlay would provoke improvisation as outlined in the previous post, proved correct, and that iMorphia in its current form is a constrained environment with little scope for improvisation.
The last workshop tested out whether having two performers transformed at the same time might encourage improvisation. We found this was not the case and that a third element or some sort of improvisational structure was required. The latest version of iMorphia features a backdrop and a virtual ball embodied with physics which interacts with the feet and hands of the two projected characters. This resulted in some game playing between the performers, but facilitated a limited and constrained form of improvisation centred around a game. The difference between game and play and the implications for the future development of iMorphia are outlined at the end of this post.
In contrast, PopUpPlay, though requiring myself as operator of the system, resulted in a great deal of improvisation and play as exemplified in the video below.
OBSERVATIONS
1. Mirroring
The first workshop highlighted the confusion between left and right arms and feet when a performer attempted to either kick a virtual ball or reach out to a virtual object. This confusion had been noted in previous studies and is due to the unfamiliar third person perspective relayed to the video glasses from the video camera located in the position of an audience member.
Generally the only time we see ourselves is in a mirror and as a result have become trained to accepting seeing ourselves horizontally reversed in the mirror. In the second workshop I positioned a mirror in front of the camera at 45 degrees so as to produce a mirror image of the stage in the video glasses.
I tested the effect using the iMorphia system and was surprised how comfortable and familiar the mirrored video feedback felt and had no problems working out left from right and interacting with the virtual objects on the intermedial stage. This effectiveness of the mirrored feedback was also confirmed by the two participants in the second workshop.
2. Gaming and playing The video highlights how PopUpPlay successfully facilitated improvisation and play, whilst iMorphia, despite the adding of responsive seagulls to the ball playing beach scene, resulted in a constrained game-like environment, where performers simply played a ball passing game with each other. Another factor to be recognised is the role of the operator in PopUpPlay, where I acted as a ‘Wizard of Oz’ behind the scenes director, controlling and influencing the improvisation through the choice of the virtual objects and their on-screen manipulation. My ideal would be to make such events automatic and embody these interaction within iMorphia.
We discussed the differences between iMorphia and PopUpPlay and also the role of the audience, how might improvisation on the intermedial stage work from the perspective of an audience? How might iMorphia or PopUp Play be extended so as to engage both performer and audience?
All the performers felt that there were times when they wanted to be able to move into the virtual scenery, to walk down the path of the projected forest and to be able to navigate the space more fully. We felt that the performer should become more like a shamanistic guide, able to break through the invisible walls of the virtual space, to open doors, to choose where they go, to perform the role of an improvisational storyteller, and to act as a guide for the watching audience.
The vision was that of a free open interactive space, the type of spaces present in modern gaming worlds, where players are free to explore where they go in large open environments. Rather than a gaming trope, the worlds would be designed to encourage performative play rather than follow typical gaming motifs of winning, battling, scoring and so on. The computer game “Myst” (1993) was mentioned as an example of the type of game that embodied a more gentle, narrative, evocative and exploratory form of gaming.
3. Depth and Interaction
The above ideas though rich with creative possibilities highlight some of the technical and interactive challenges when combining real bodies on a three dimensional stage with a virtual two dimensional projection. PopUpPlay utilises two dimensional backdrops and the movements of the virtual objects are constrained to two dimensions – although the illusion of distance can be evoked by changing the size of the objects. IMorphia on the other hand is a simulated three dimensional space. The interactive ball highlighted interaction and feedback issues associated with the z or depth dimension. For a participant to kick the ball their foot had to be colocated near to the ball in all three dimensions. As the ball rested on the ground the y dimension was not problematic, the x dimension, left and right, was easy to find, however depth within the virtual z dimension proved very difficult to ascertain, with performers having to physically move forwards and backwards in order to try and move the virtual body in line with the ball. The video glasses do not provide any depth cues of the performer in real or virtual space, and if performers are to be able to move three dimensionally in both the real and the virtual spaces in such a way that colocation and thereby real/virtual body/object interactions can occur, then a method for delivering both virtual and real world depth information will be required.
On Thursday 26th February 2015 I attended the launch of Pop Up Play at De Montford University, a free “Open Source” mixed reality toolkit for schools.
The experience of PopUpPlay was described as a hybrid mix of theatre, film, game and playground.
It was extremely refreshing and inspiring to witness the presentation of the project and experience a live hands-on demonstration of the toolkit.
The presentation included case studies with videos showing how children used the system and feedback from teachers and workshop leaders on its power and effectiveness.
Feedback from the trials indicated how easily and rapidly children took to the technology, mastering the controls and creating content for the system.
What was especially interesting in the light of iMorphia was the open framework and inherent intermedial capabilities presented by the system. A simple interface enabled the control of background images, webcam image input and kinect 3D body sensing, as well as control of DMX lights and the inclusion of audio and special effects .
The system also supported a wireless iPad tablet presenting a simplified and robust control interface designed for children, rather than the more feature rich computer interface. The touchable interface also enabled modification of images through familiar touch screen gestures such as pinch, expand rotate and slide.
“The overarching aims of this research project were to understand how Arts and cultural organisations can access digital technology for creative play and learning, and how we can enable children and young people to access meaningful digital realm engagement.
In response to this our specific objectives were to create a mixed reality play system and support package that could:
Immerse participants in projected images and worlds
Enable children to invest in the imaginary dimensions and possibilities of digital play
provide a creative learning framework, tools, guides and manuals and an online community
Offer open source software, easy to use for artists, learning officers, teachers, librarians, children and young people”
Two interesting observations drawn by the research team from the case studies were the role playing of the participants and the design of a set of ideation cards to help stimulate creative play.
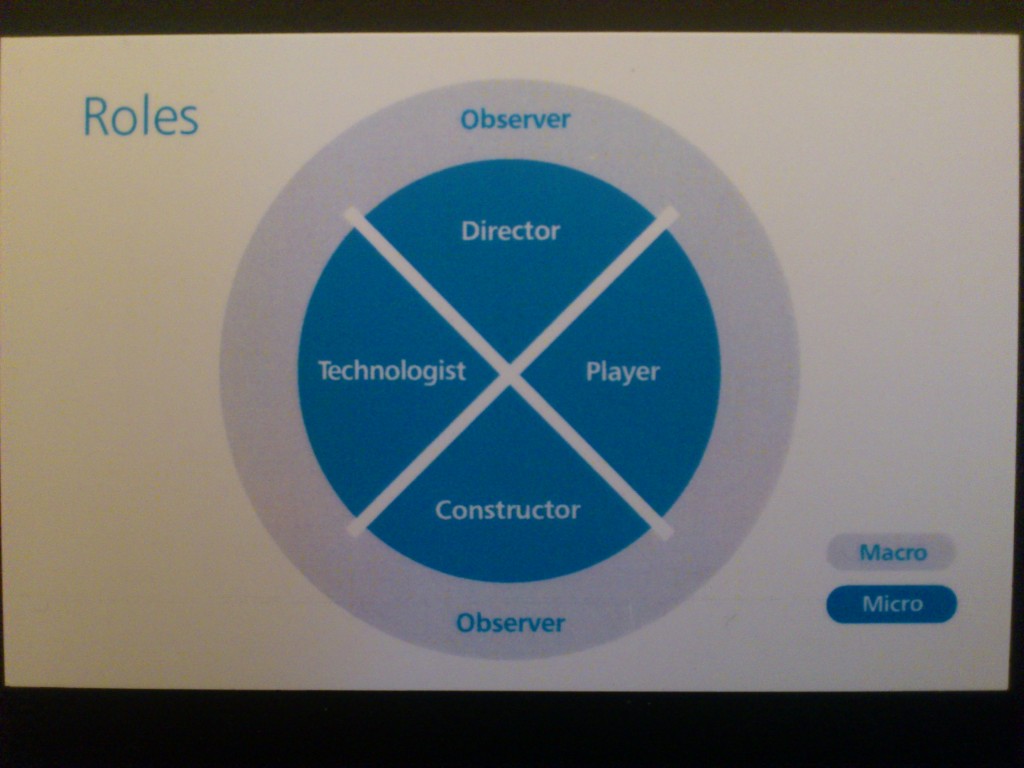
Participants tended to adopt the roles of Technologist, Director, Player, Constructor and Observer. Though they might also swap or take on multiple roles throughout the experience.
The ideation cards supplied suggestions for activities or actions based on four categories
Change, Connect, Create and Challenge.
Change – change a parameter in the system.
Connect – carry out an action that makes connections in the scene.
Create – create something to be used in the scene.
Challenge – a new task to be carried out.
An interesting observation was that scenes generally did not last more than 3 minutes before the children became bored and something was required to change the scene in some way, hence the use of the ideation cards.
The use of ideation cards as a means of shaping or catalysing performative practise echoes one of the problems Jo Scott mentioned when a system is too open, that there would be nowhere to go and some shaping or steering mechanism was required.
A number of audience members commented on the lack of narrative structure, though the team felt that children were quite happy to make it up as they went along and the system embodied a new ontology, an iterative process moving between moment to moment which represented a new practise within creative play.
Through the Looking Glass
One of the weaknesses of the system I felt was the television screen aspect where participants watched the mixed reality on a screen in front of themselves, as if looking upon a digital mirror, which tended to cause a breakdown of the immersive effect when participants looked at each other. I felt there were problems with this approach and one of the interesting aspects of iMorphia was the removal of the watched screen, instead one watched oneself from the perspective of the audience. It would be interesting to combine Pop Up Play with the third person viewing technique utilised in iMorphia.
The lack of support for improvisation within iMorphia could be potentially addressed by the Pop Up Play interface. Though the system enables individual elements to be loaded at any time it does not currently support a structure that would enable scenes or narrative structures to be created or recalled, nor transitions between scenes to be created in the form of a trajectory. Though advertised as OpenSource, the actual system is implemented in MaxMSP which would require a license to be able to modify or add to the software.
Though very inspiring, I was viewing the system from the perspective of questioning how it might be used in live performance. Apart from the need for a hyper structure to enable the recall of scenes another problematic aspect was the need for the subject to be brightly illuminated by a very bright white LED lamp. This is a problem I also encountered when testing out face tracking, it would only work when the face was sufficiently illuminated. The Kinect webcam requires sufficient illumination to be able to “see”, unlike its inbuilt infra-red 3D tracking capability. This need for lighting then clashes with the projectors requirement of a near dark environment. Perhaps infra-red illumination or a “nightvision” low lux webcam might solve this problem.
Performative Interaction and Embodiment on an Augmented Stage